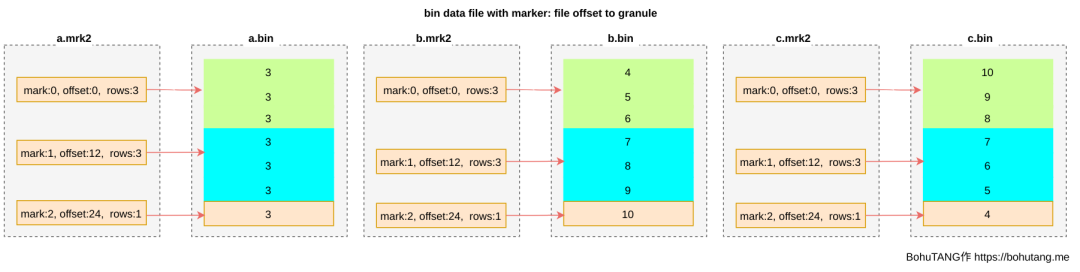
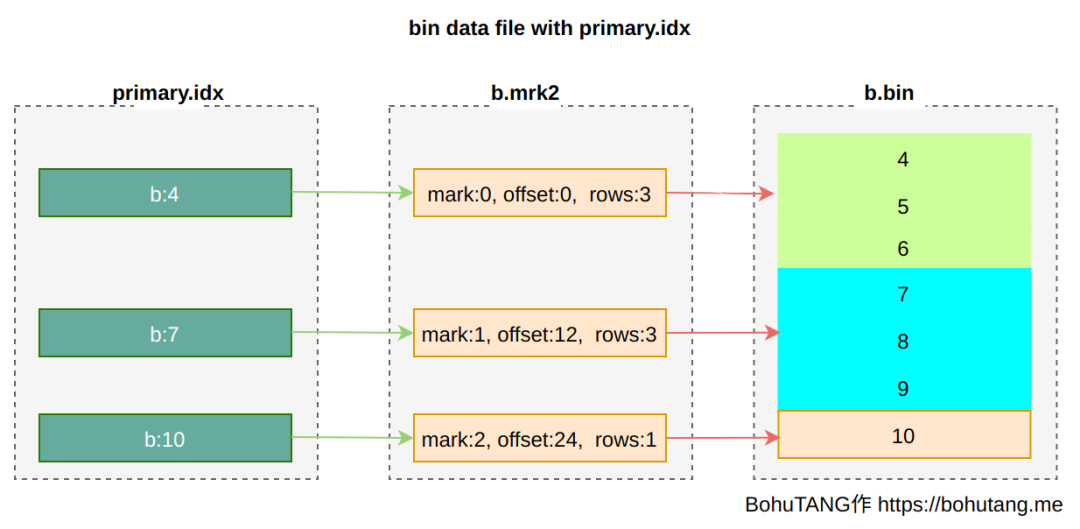
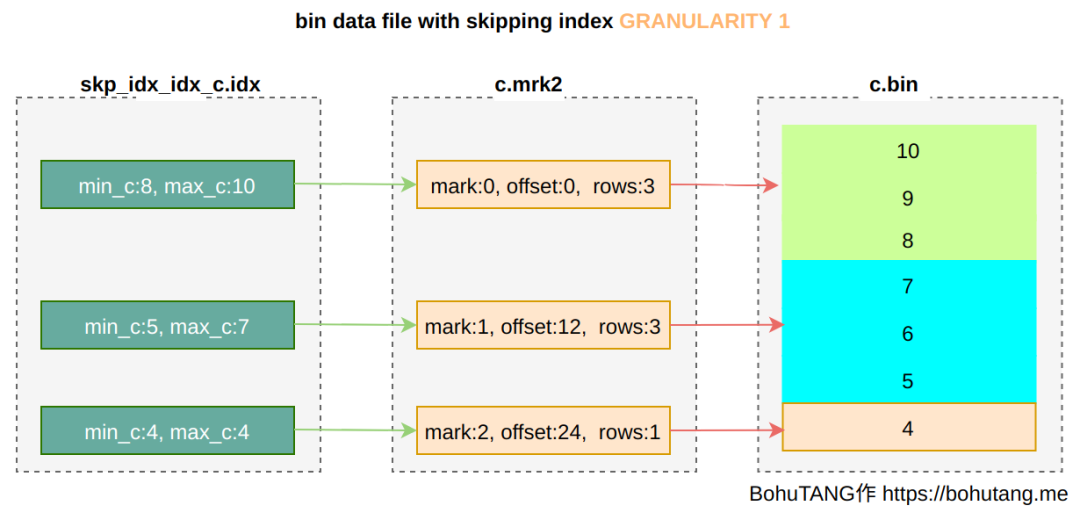
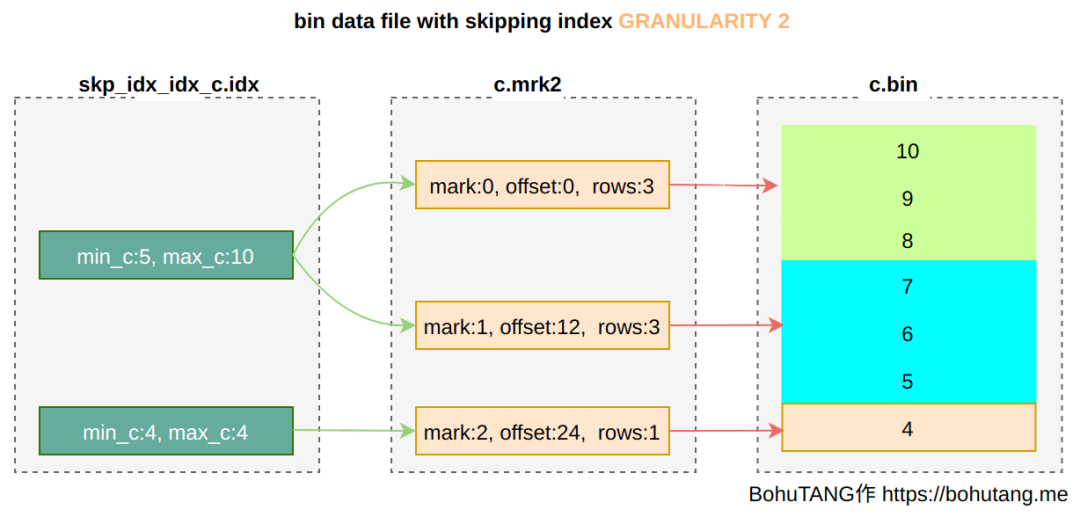
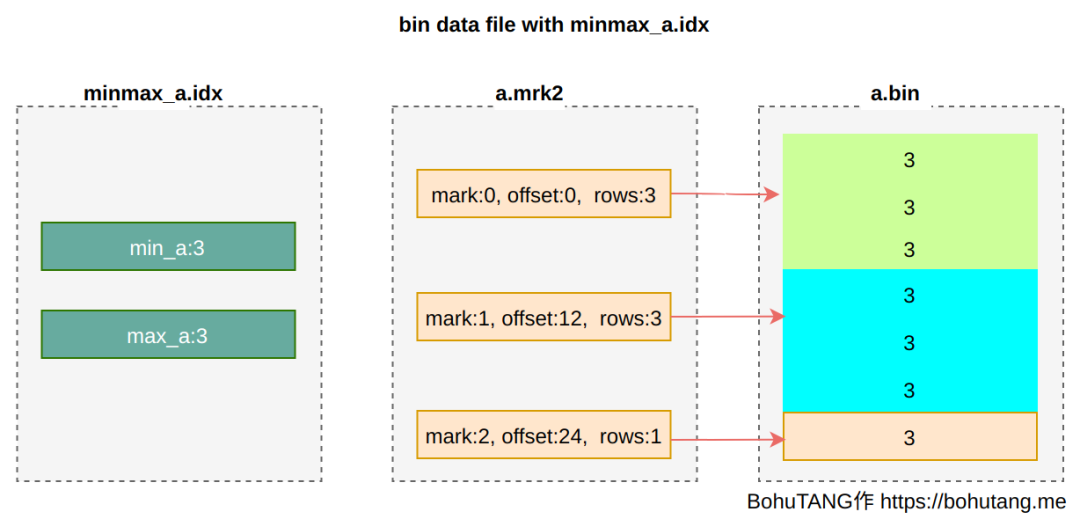
各位,今年 ClickHouse 最王炸的功能来啦,没错,就是期待已久的 Projection (投影) 功能。ClickHouse 现在的功能已经非常丰富强大了,但是社区用现实告诉我们,还可以进一步做的更好:)
不知道你有没有碰到过这些情况:
建表的时候,Order By 同时决定了主键稀疏索引和数据的排序,假设 :
Order BY A , B , C 那么通常过滤查询 Where A 会很快,但是 Where C 会慢一些。
针对固定的查询主题,我们会基于一张底表构建许多物化视图,以帮助更进一步提升查询性能、提升QPS、降低资源开销。
物化视图虽然效果显著,但是却不够智能。物化视图本质上一张独立的表,通过原表的触发器,实时的向视图表写入数据。
既然物化视图也是独立的表,那么自然就会存在与原表数据一致性的问题。如果物化视图很多,维护起来也是一个问题。
Projection 功能的出现,完美解决了上述的问题 。Projection 的概念出自 《C-Store: A Column-oriented DBMS》这篇论文,作者是2015年图灵奖获得者、Vertica 之父,Mike Stonebraker。
Projection 意指一组列的组合,可以按照与原表不同的排序存储,并且支持聚合函数的查询。
来自快手的 Amos Bird(郑天祺) 借鉴了这个思想,在 ClickHouse 中实现了 Projection 的功能,并贡献到社区。
ClickHouse Projection 可以看做是一种更加智能的物化视图,它有如下特点:
part-level 存储
相比普通物化视图是一张独立的表,Projection 物化的数据就保存在原表的分区目录中,支持明细数据的普通Projection 和 预聚合Projection无感使用,自动命中
可以对一张 MergeTree 创建多个 Projection ,当执行 Select 语句的时候,能根据查询范围,自动匹配最优的 Projection 提供查询加速。如果没有命中 Projection , 就直接查询底表。
数据同源、同生共死 因为物化的数据保存在原表的分区,所以数据的更新、合并都是同源的,也就不会出现不一致的情况了
这么干讲可能还比较抽象,直接来看用例吧,这里直接使用官方的测试数据集 hits_100m_obfuscated,这张表有 1亿 数据:
SELECT count ( * )
FROM hits_100m_obfuscated
Query id: 813 ba930- d299- 47 d8- 9 ac3- 6 d7dbde075b1
┌───count ( ) ─┐
│ 100000000 │
└───────────┘
1 rows in set. Elapsed: 0.004 sec. Order By 是:
ENGINE = MergeTree
PARTITION BY toYYYYMM ( EventDate)
ORDER BY ( CounterID, EventDate, intHash32 ( UserID) , EventTime) 在没有 Projection 的时候,查询非主键 WatchID:
SELECT WatchID
FROM hits_100m_obfuscated
WHERE WatchID = 5814563137538961516
Query id: 20110 b52- cac0- 43 b7- baf6- 1931 b94864a6
┌─────────────WatchID─┐
│ 5814563137538961516 │
└─────────────────────┘
1 rows in set. Elapsed: 0.262 sec. Processed 100.00 million rows, 800.00 MB ( 380.95 million rows/ s. , 3.05 GB / s. ) 结果全表扫描了 800MB 共 1亿行数据。
现在创建一个 Projection ,为特定的 Where 字段加速,按查询的需求生成有别于主键的,另外一种排序规则:
ALTER TABLE hits_100m_obfuscated ADD PROJECTION p1
(
SELECT
WatchID, Title
ORDER BY WatchID
) 注意,只有在创建 PROJECTION 之后,再被写入的数据,才会自动物化。
对于历史数据,需要手动触发物化,例如现在我们就需要执行:
alter table hits_100m_obfuscated MATERIALIZE PROJECTION p1 MATERIALIZE PROJECTION 是一个异步的 Mutation 操作,可以通过下面的语句查询状态:
SELECT
table,
mutation_id,
command,
is_done
FROM system. mutations AS m
WHERE is_done = 0
Query id: 7 ddc855a- acb5- 4 ca9- 8 c48- ad4f5a7b234e
┌─table────────────────┬─mutation_id─────┬─command───────────────────┬─is_done─┐
│ hits_100m_obfuscated │ mutation_99. txt │ MATERIALIZE PROJECTION p1 │ 0 │
└──────────────────────┴─────────────────┴───────────────────────────┴─────────┘
1 rows in set. Elapsed: 0.005 sec. 这个时候,如果我们去分区目录,你会看到一个 tmp 临时分区,正在物化 PROJECTION 的数据:
等到 p1 PROJECTION 生成好了之后,我们再去看分区目录:
会看到在原有 MergeTree 的分区下,多了一个 p1.proj 的子目录,进入子目录,你会发现和 MergeTree 的存储格式是一样的:
cd / data/ default / hits_100m_obfuscated/ 201307_1 _96_4_107/ p1. proj
[ root@ch9 p1. proj] # ll
total 5187772
- rw- r-- -- - . 1 clickhouse clickhouse 278 Sep 8 23 : 43 checksums. txt
- rw- r-- -- - . 1 clickhouse clickhouse 69 Sep 8 23 : 43 columns. txt
- rw- r-- -- - . 1 clickhouse clickhouse 9 Sep 8 23 : 43 count. txt
- rw- r-- -- - . 1 clickhouse clickhouse 10 Sep 8 23 : 43 default_compression_codec. txt
- rw- r-- -- - . 1 clickhouse clickhouse 97672 Sep 8 23 : 43 primary. idx
- rw- r-- -- - . 1 clickhouse clickhouse 4508224709 Sep 8 23 : 43 Title. bin
- rw- r-- -- - . 1 clickhouse clickhouse 293016 Sep 8 23 : 43 Title. mrk2
- rw- r-- -- - . 1 clickhouse clickhouse 803340103 Sep 8 23 : 43 WatchID. bin
- rw- r-- -- - . 1 clickhouse clickhouse 293016 Sep 8 23 : 43 WatchID. mrk2 当查询命中某个 PROJECTION 的时候,就会直接用分区子目录中的数据,来提供查询。
再有了 p1 PROJECTION 之后,再次执行同样的查询,记得首先要设置参数开启这项功能:
SET allow_experimental_projection_optimization = 1 ; 执行查询:
SELECT WatchID
FROM hits_100m_obfuscated
WHERE WatchID = 5814563137538961516
Query id: 38 d2aa48- 45 da- 4487 - ab80- 1 cd02ee08ce2
┌─────────────WatchID─┐
│ 5814563137538961516 │
└─────────────────────┘
1 rows in set. Elapsed: 0.006 sec. Processed 8.19 thousand rows, 65.54 KB ( 1.41 million rows/ s. , 11.27 MB / s. ) 效果惊人,从 800MB 的 1亿 行全表扫描,缩减到 65KB 的 8k 行扫描,时间也加快了 40 多倍。
除了明细数据的查询,PROJECTION 也支持预聚合, 在没有优化的情况下,下面的查询也会全表扫描:
SELECT
UserID,
SearchPhrase,
count ( )
FROM hits_100m_obfuscated
GROUP BY
UserID,
SearchPhrase
LIMIT 10
Query id: 42 c941e0- c15a- 4206 - 9 c1b- 7350 a5a67984
┌───────────────UserID─┬─SearchPhrase─────────────────────────────────────────────────┬─count ( ) ─┐
│ 64240392369242065 │ │ 1 │
│ 2542641703475366060 │ galaxy s4 activerstovmamasumi x2 │ 3 │
│ 14973463213479722228 │ │ 17 │
│ 6604743450870066038 │ │ 1 │
│ 325929602194382277 │ вес гриппи игре aventity of wars 2 в в играть │ 1 │
│ 5481644077966220011 │ как леченский рецепты как почему конкая лето москва отдых на │ 1 │
│ 5965198553492672379 │ │ 1 │
│ 119657425828985633 │ │ 1 │
│ 8462750442030450647 │ рулонасточный+ статив зомбинет магазин на айресу батл │ 1 │
│ 7510587892824469257 │ sia 265 сезон 6 серии │ 1 │
└──────────────────────┴──────────────────────────────────────────────────────────────┴─────────┘
10 rows in set. Elapsed: 2.190 sec. Processed 100.00 million rows, 2.44 GB ( 45.66 million rows/ s. , 1.11 GB / s. ) 现在创建另外一个聚合 PROJECTION:
ALTER TABLE hits_100m_obfuscated ADD PROJECTION agg_p2
(
SELECT
UserID,
SearchPhrase,
count ( )
GROUP BY UserID, SearchPhrase
) 由于历史数据已经存在,也要手动触发一下物化:
alter table hits_100m_obfuscated MATERIALIZE PROJECTION agg_p2 物化好了之后,再次执行相同的查询:
SELECT
UserID,
SearchPhrase,
count ( )
FROM hits_100m_obfuscated
GROUP BY
UserID,
SearchPhrase
LIMIT 10
Query id: 258e556 e- ea5b- 43 f0- 980 a- 997 c02abc233
┌───────────────UserID─┬─SearchPhrase─────────────────────────────────────────────────┬─count ( ) ─┐
│ 64240392369242065 │ │ 1 │
│ 2542641703475366060 │ galaxy s4 activerstovmamasumi x2 │ 3 │
│ 14973463213479722228 │ │ 17 │
│ 6604743450870066038 │ │ 1 │
│ 325929602194382277 │ вес гриппи игре aventity of wars 2 в в играть │ 1 │
│ 5481644077966220011 │ как леченский рецепты как почему конкая лето москва отдых на │ 1 │
│ 5965198553492672379 │ │ 1 │
│ 119657425828985633 │ │ 1 │
│ 8462750442030450647 │ рулонасточный+ статив зомбинет магазин на айресу батл │ 1 │
│ 7510587892824469257 │ sia 265 сезон 6 серии │ 1 │
└──────────────────────┴──────────────────────────────────────────────────────────────┴─────────┘
10 rows in set. Elapsed: 1.847 sec. Processed 24.07 million rows, 1.58 GB ( 13.04 million rows/ s. , 856.09 MB / s. ) 数据扫描范围减少了四分之三。
现在 ClickHouse 也提供了 PROJECTION 的系统表,可以看到相关的存储信息:
SELECT
name,
partition,
formatReadableSize ( bytes_on_disk) AS bytes,
formatReadableSize ( parent_bytes_on_disk) AS parent_bytes,
parent_rows,
rows / parent_rows AS ratio
FROM system. projection_parts
Query id: 2887 b0e1- b984- 4274 - 862 c- 0 b59c68693c5
┌─name───┬─partition─┬─bytes──────┬─parent_bytes─┬─parent_rows─┬──────ratio─┐
│ agg_p2 │ 201307 │ 490.40 MiB │ 14.06 GiB │ 100000000 │ 0.24070565 │
│ p1 │ 201307 │ 4.95 GiB │ 18.53 GiB │ 100000000 │ 1 │
└────────┴───────────┴────────────┴──────────────┴─────────────┴────────────┘PROJECTION 本质也是在用空间换时间,还是还很划算的。
PROJECTION 也支持删除的 DDL:
ALTER TABLE hits_100m_obfuscated DROP PROJECTION p1
ALTER TABLE hits_100m_obfuscated DROP PROJECTION agg_p2 除了通过 ALTER 创建,也能在 CREATE TABLE 的时候创建,例如:
CREATE TABLE xxx
(
` event_key ` ,
` user ` ,
` dim1 ` ,
PROJECTION p1
(
SELECT
groupBitmap ( user) ,
count ( 1 )
GROUP BY dim1
)
)
ENGINE = MergeTree ( )
ORDER BY ( event_key, user) 通过刚才的例子,你能发现在查询时, PROJECTION 的使用是无感的,ClickHouse 会根据提交的 SQL 语句自动匹配。
那么你肯定会好奇,匹配的规则是什么呢?有这么几条原则:
1. 设置了 SET allow_experimental_projection_optimization = 1
2. 返回的数据行小于基表总数
3. 查询覆盖的分区 part 超过一半
4. Where 必须是 PROJECTION 定义中 GROUP BY 的子集
5. GROUP BY 必须是 PROJECTION 定义中 GROUP BY 的子集
6. SELECT 必须是 PROJECTION 定义中 SELECT 的子集
7. 匹配多个 PROJECTION 的时候,选取读取 part 最少的
如果你不知道查询是否匹配了 PROJECTION ,有两种方式可以校验:
1. 使用 explain ,例如:
EXPLAIN
SELECT WatchID
FROM hits_100m_obfuscated
WHERE WatchID = 5814563137538961516
Query id: bf008e69- fd68- 4928 - 83 f6- a57a2d84e286
┌─explain───────────────────────────────────────────────────────────────────┐
│ Expression ( ( Projection + Before ORDER BY ) ) │
│ SettingQuotaAndLimits ( Set limits and quota after reading from storage) │
│ ReadFromStorage ( MergeTree ( with 0 projection p1) ) │
└───────────────────────────────────────────────────────────────────────────┘看到 MergeTree(with 0 projection p1) 就代表这条 SQL 查询会命中 PROJECTION
2. 查看执行日志:
( SelectExecutor) : Choose normal projection p3
( SelectExecutor) : projection required columns: dim1, dim3, event_time, dim2, event_key, user
( SelectExecutor) : Key condition: ( column 0 in [ 'dim12' , 'dim12' ] ) 看到 Choose xxx projection 就代表这条 SQL 查询已经命中 PROJECTION
利用 PROJECTION ,我们只需面对一张底表查询就行了,既拥有原来物化视图的性能,又免去了维护成本和数据一致性的问题,简直无敌啊。
好了,今天的分享就到这里,再有了 PROJECTION 之后,可以说 ClickHouse 更加的如虎添翼了。在原有的一些场景下,我们可以告别 ETL和物化视图了。
from: https://cloud.tencent.com/developer/article/1878609