上篇的 儲存引擎技術進化與MergeTree 介紹了儲存演算法的演進。
CREATE TABLE default.mt
(
`a` Int32,
`b` Int32,
`c` Int32,
INDEX `idx_c` (c) TYPE minmax GRANULARITY 1
)
ENGINE = MergeTree
PARTITION BY a
ORDER BY b
SETTINGS index_granularity=3
insert into default.mt(a,b,c) values(1,1,1);
insert into default.mt(a,b,c) values(5,2,2),(5,3,3);
insert into default.mt(a,b,c) values(3,10,4),(3,9,5),(3,8,6),(3,7,7),(3,6,8),(3,5,9),(3,4,10);
磁碟檔案
ls ckdatas/data/default/mt/
1_4_4_0 3_6_6_0 5_5_5_0 detached format_version.txt
ls ckdatas/data/default/mt/3_6_6_0/
a.bin a.mrk2 b.bin b.mrk2 c.bin checksums.txt c.mrk2 columns.txt count.txt minmax_a.idx partition.dat primary.idx skp_idx_idx_c.idx skp_idx_idx_c.mrk2
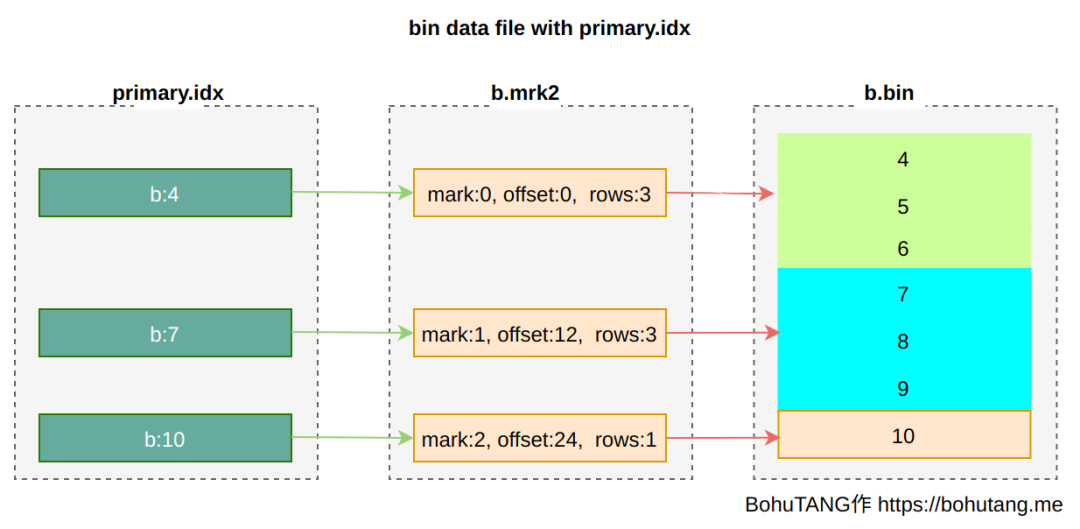
*.bin 是列資料檔案,按主鍵排序(ORDER BY),這裡是按照欄位 b 進行排序 *.mrk2 mark 檔案,目的是快速定位 bin 檔案資料位置 minmax_a.idx 分割槽鍵 min-max 索引檔案,目的是加速分割槽鍵 a 查詢 primay.idx 主鍵索引檔案,目的是加速主鍵 b 查詢 skp_idx_idx_c.* 欄位 c 索引檔案,目的是加速 c 的查詢
儲存結構
資料檔案
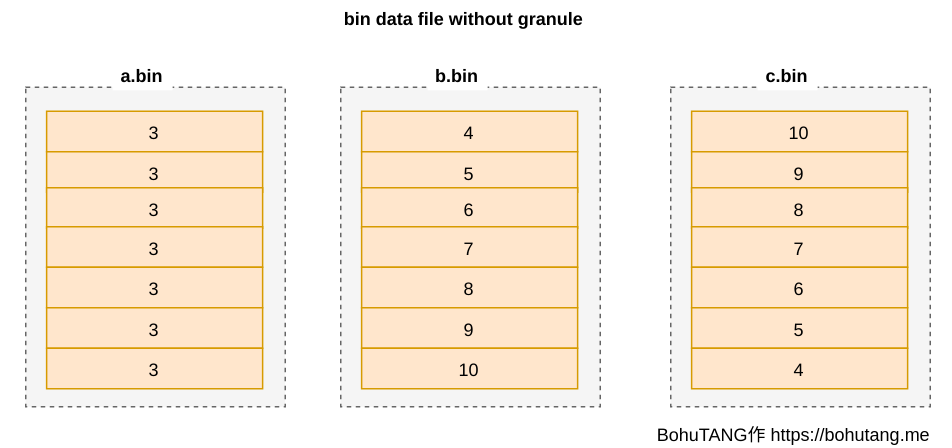
granule
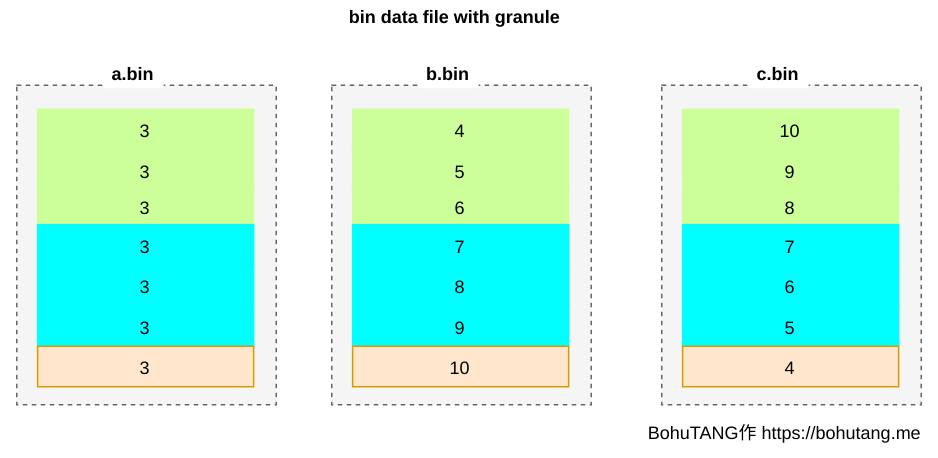
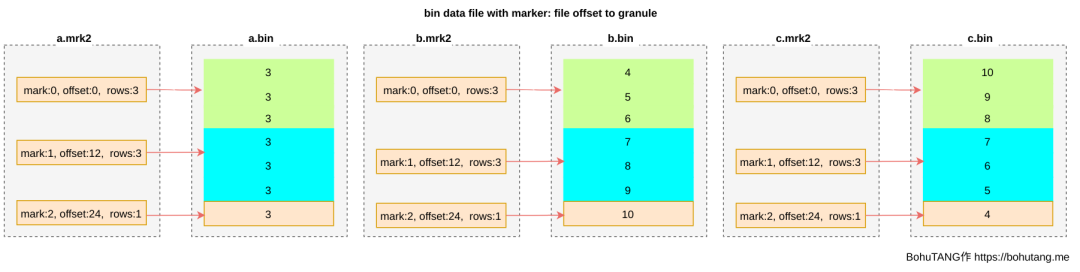
根據查詢條件確定需要哪些 mark 根據 mark 讀取相應的 granule
儲存排序

稀疏索引
1. primary index
2. skipping index
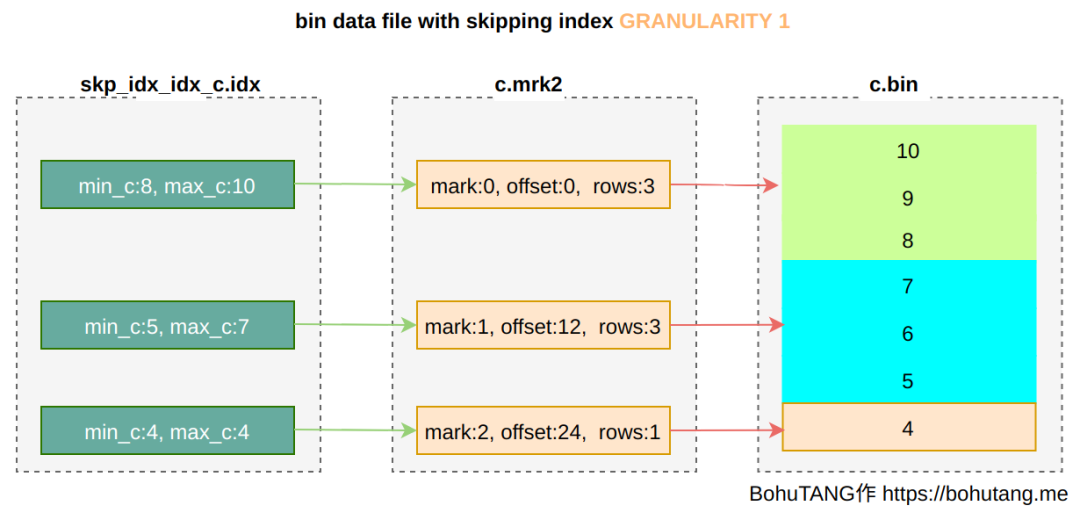
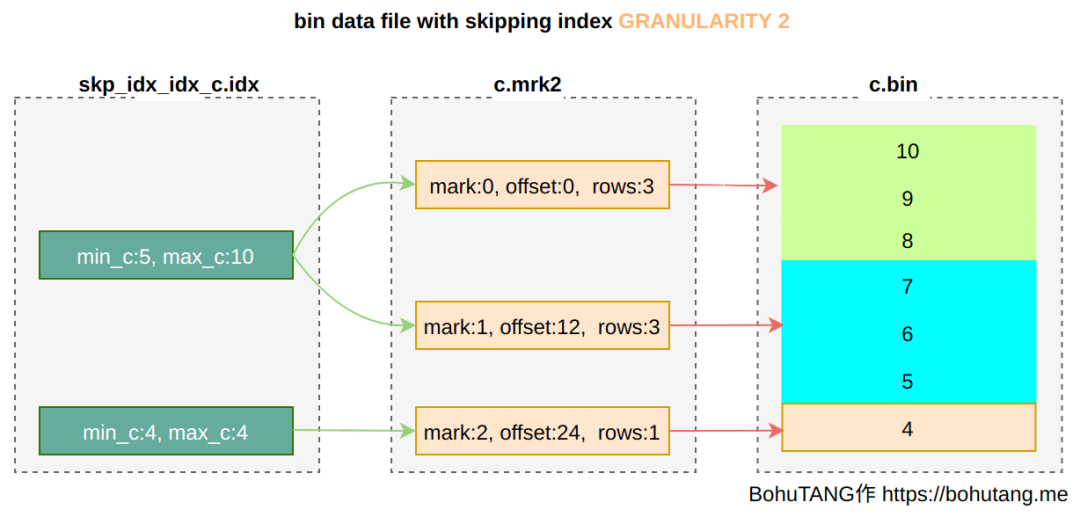
3. partition minmax index
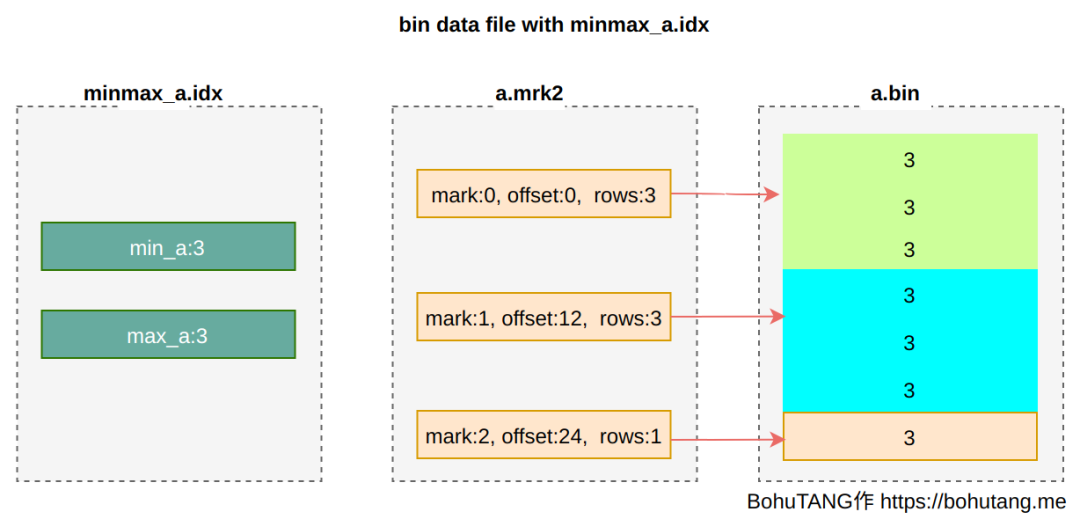
4. 全景圖

查詢優化
1. 分割槽鍵查詢
select * from default.mt where a=3
<Debug> InterpreterSelectQuery: MergeTreeWhereOptimizer: condition "a = 3" moved to PREWHERE
<Debug> default.mt (SelectExecutor): Key condition: unknown
<Debug> default.mt (SelectExecutor): MinMax index condition: (column 0 in [3, 3])
<Debug> default.mt (SelectExecutor): Selected 1 parts by a, 1 parts by key, 3 marks by primary key, 3 marks to read from 1 ranges
┌─a─┬──b─┬──c─┐
│ 3 │ 4 │ 10 │
│ 3 │ 5 │ 9 │
│ 3 │ 6 │ 8 │
│ 3 │ 7 │ 7 │
│ 3 │ 8 │ 6 │
│ 3 │ 9 │ 5 │
│ 3 │ 10 │ 4 │
└───┴────┴────┘
2. 主鍵索引查詢
select * from default.mt where b=5
<Debug> default.mt (SelectExecutor): Key condition: (column 0 in [5, 5])
<Debug> default.mt (SelectExecutor): MinMax index condition: unknown
<Debug> default.mt (SelectExecutor): Selected 3 parts by a, 1 parts by key, 1 marks by primary key, 1 marks to read from 1 ranges
┌─a─┬─b─┬─c─┐
│ 3 │ 5 │ 9 │
└───┴───┴───┘
3. 索引查詢
select * from default.mt where b=5
<Debug> InterpreterSelectQuery: MergeTreeWhereOptimizer: condition "c = 5" moved to PREWHERE
<Debug> default.mt (SelectExecutor): Key condition: unknown
<Debug> default.mt (SelectExecutor): MinMax index condition: unknown
<Debug> default.mt (SelectExecutor): Index `idx_c` has dropped 1 / 1 granules.
<Debug> default.mt (SelectExecutor): Index `idx_c` has dropped 1 / 1 granules.
<Debug> default.mt (SelectExecutor): Index `idx_c` has dropped 2 / 3 granules.
<Debug> default.mt (SelectExecutor): Selected 3 parts by a, 1 parts by key, 5 marks by primary key, 1 marks to read from 1 ranges
┌─a─┬─b─┬─c─┐
│ 3 │ 9 │ 5 │
└───┴───┴───┘
總結
from: https://www.gushiciku.cn/pl/pS3b/zh-tw

No comments:
Post a Comment